

Otro día, otro modelo de IA de Google. Esta vez, Google DeepMind ha lanzado un nuevo miembro de la familia de modelos abiertos Gemma 4, pero es fundamentalmente diferente del resto de la gama de modelos. DiffusionGemma no produce resultados de forma lineal como la mayoría de los modelos de IA. En cambio, puede generar bloques enteros de texto en paralelo. Google dijo esto lo hace más rápido y eficiente cuando se ejecuta en hardware local como Nvidia DGX o una GPU de juegos simple.
La mayoría de los modelos de IA están diseñados para ser autorregresivos: generan texto de izquierda a derecha, un token a la vez. DiffusionGemma tiene más en común con el modelo de creación de imágenes, que comienza con estática y luego la elimina para crear el contenido deseado. Este modelo toma un campo de tokens de marcador de posición que se ejecuta sobre el lienzo varias veces para generar probabilidades de tokens y las utiliza para mejorar las estimaciones de otros tokens. Al final del proceso, el modelo completa la salida del token en un bloque grande: el lienzo de texto “rechazado”.
DiffusionGemma es bastante grande en el ámbito de los modelos abiertos de Google. Este es un modelo de Mezcla de Expertos (MoE) con un total de 26 mil millones de parámetros, pero solo 3,8 mil millones se activan durante la inferencia. Eso significa que tiene que caber en la asignación de RAM de 18 GB de una GPU de gama alta. Al realizar pruebas con un RTX 5090, DiffusionGemma emitió alrededor de 700 tokens por segundo. Con un único acelerador de IA Nvidia H100, DiffusionGemma puede generar más de 1000 tokens por segundo. Eso es aproximadamente cuatro veces la producción de un modelo Gemma autorregresivo de tamaño similar.
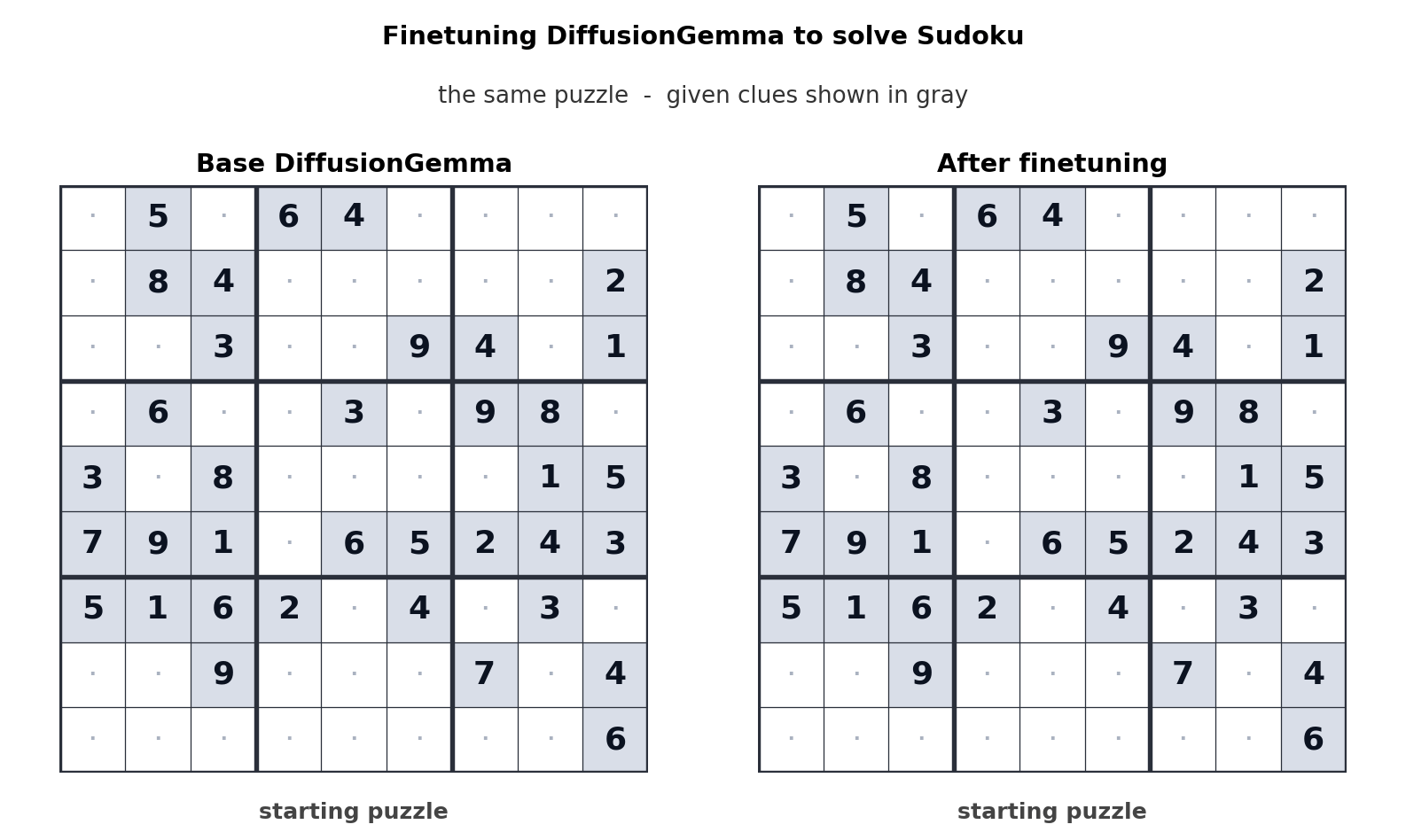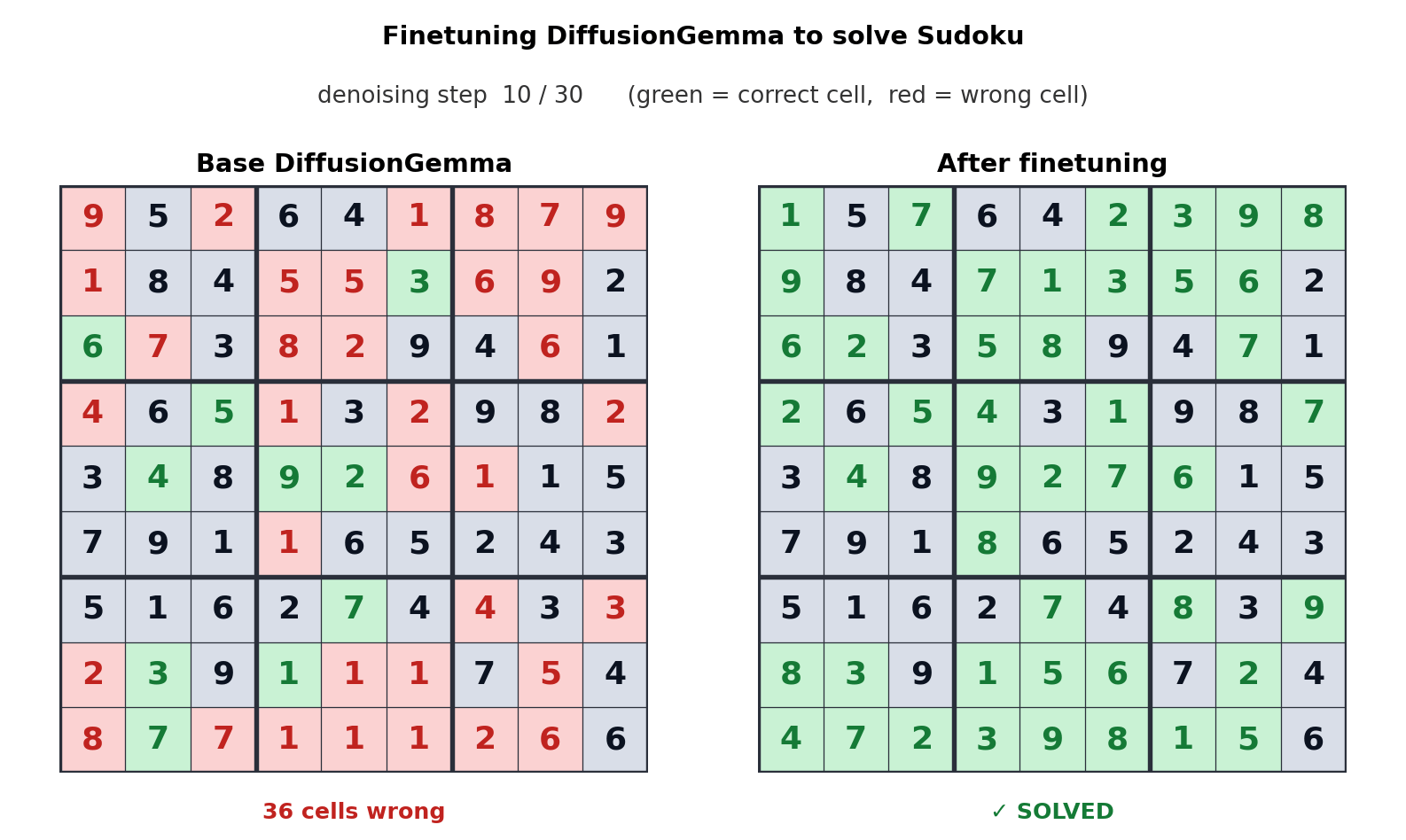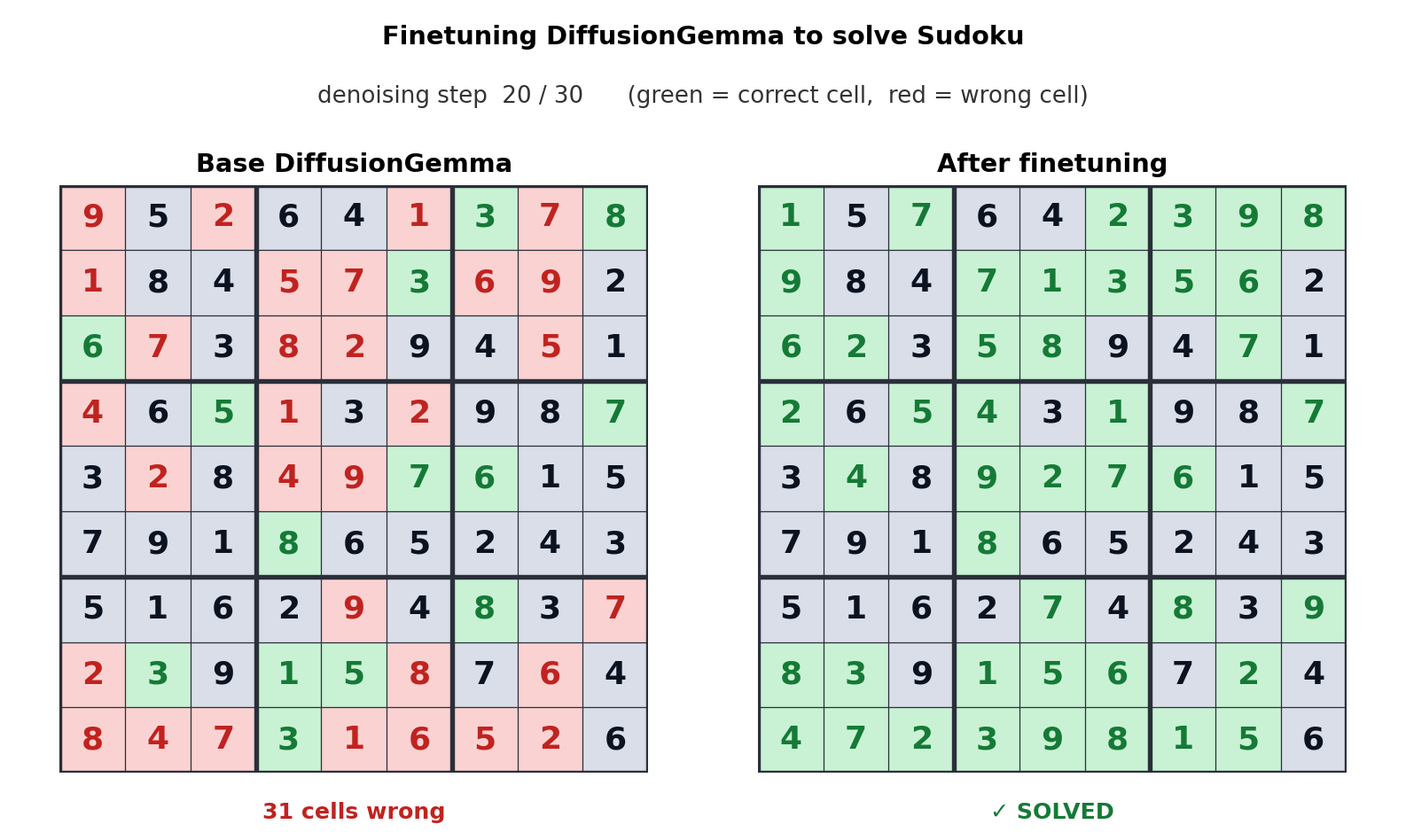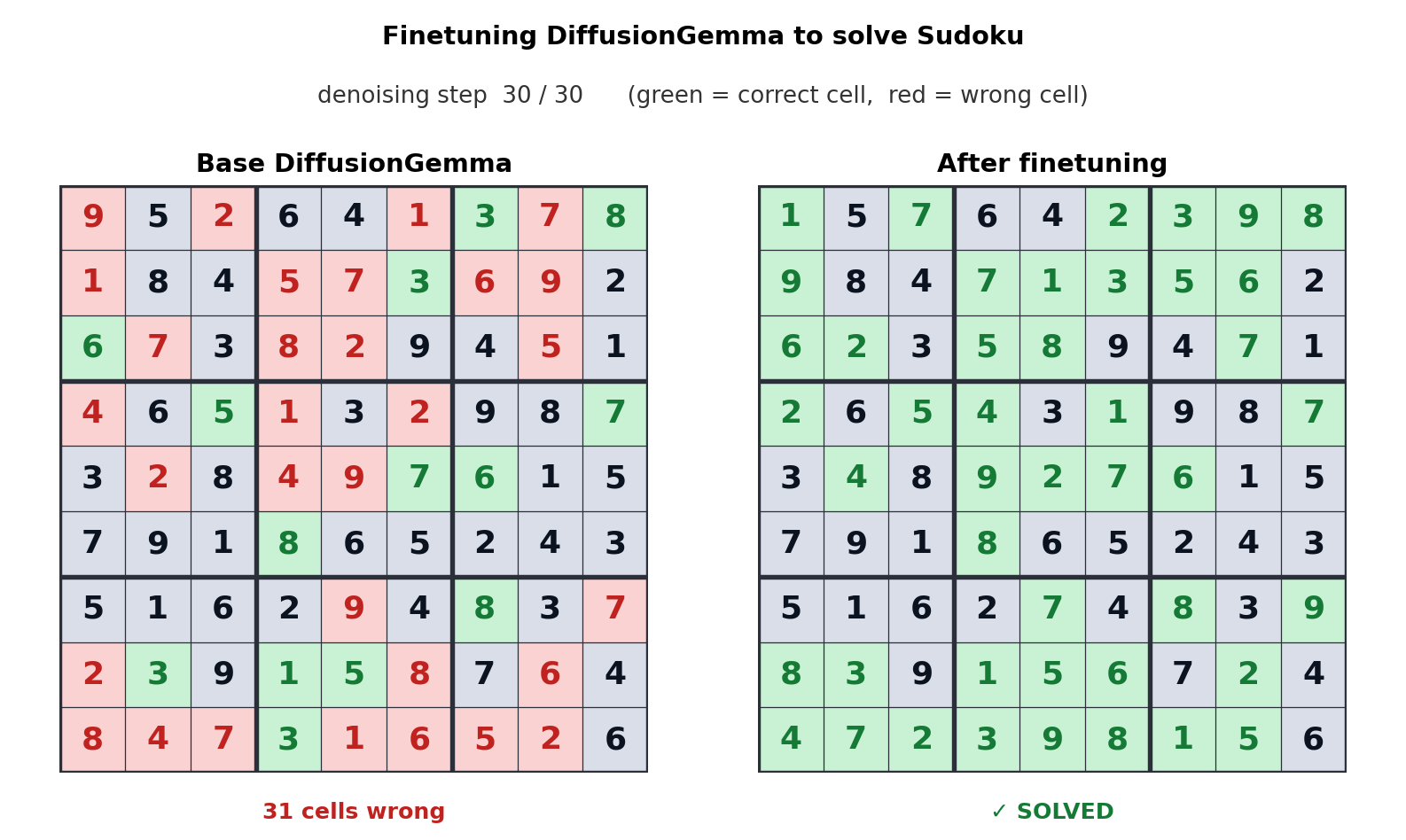
Este enfoque para la generación de texto desplaza el cuello de botella del ancho de banda de la memoria al cálculo, generando hasta 256 tokens en paralelo. Google dice que ofrece mejoras mensurables en tareas no lineales como edición en línea, secuenciación molecular y gráficos matemáticos. La animación anterior muestra cómo DiffusionGemma está optimizada para resolver un Sudoku, que es una tarea muy desafiante para los modelos de IA autorregresivos estándar porque cada token depende de tokens futuros. La capacidad de DiffusionGemma para autocorregir continuamente una gran cantidad de tokens hace que esto sea aún más fácil.



{kind=link}
{kind=link}